Image Classification#
1. Load images#
To begin, we will load the images from an example dataset included in Piximi by pressing ![]()
Open in the top left. Select Open > Project > Example Project > Human U2OS-cells example project to get started. Alternatively, if you would like to load your own images, go to Open > Image > New Image.
The images correspond to U2OS cells co-expressing arrestin-GFP and an orphan GPCR. Upon receptor stimulation arrestin-GFP is recruited to the plasma membrane and eventually endocytosed resulting in vesicle like structures.
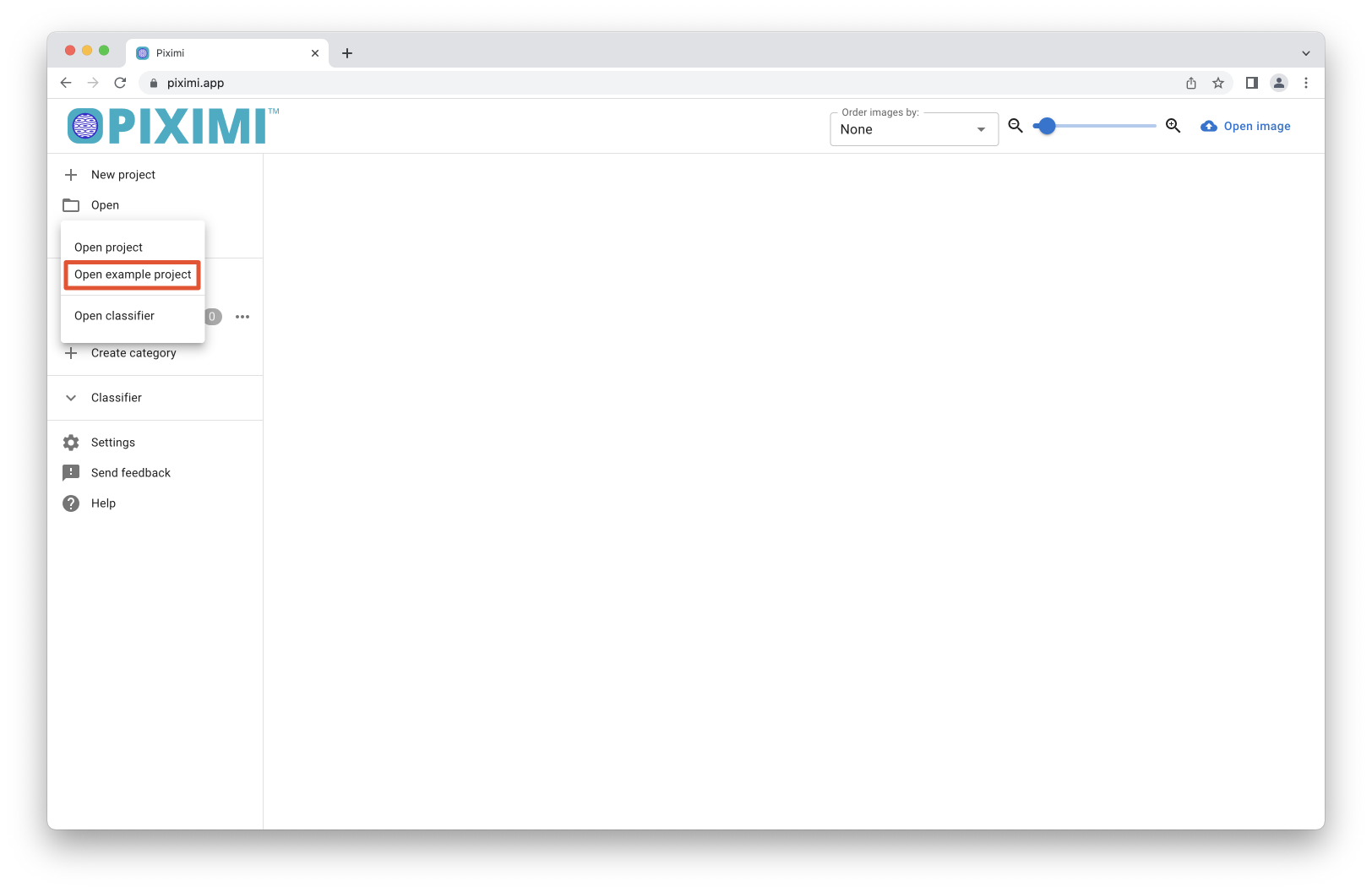
Fig. 22 Open the U2OS example dataset#
2. Categorize images#
In the Categories sub-menu on the left hand side you can see that there are already 3 classes defined for the U2OS example project. To turn on/off the display of images under a given label, click on the ![]() filters icon on the right hand panel, and toggle the label of interest under
filters icon on the right hand panel, and toggle the label of interest under By category. The classes are:
Unknown
This represents the uncategorized images. Piximi will predict which class these images belong to later
Positive Control (vesicular GFP)
Negative Control (cytoplasmic GFP)
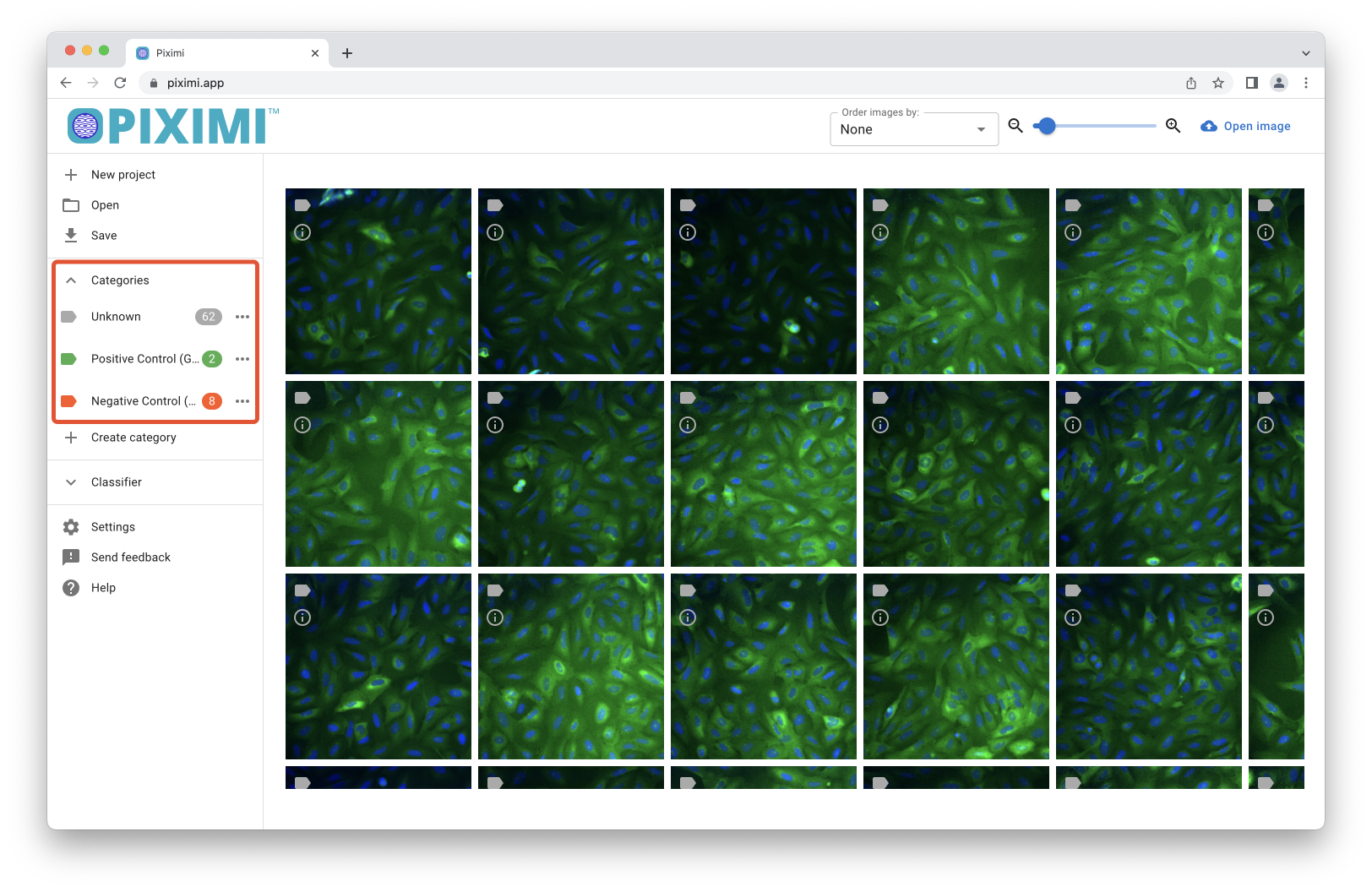
Fig. 23 Explore the category menu. Turn on/off (![]() /
/![]() ) a particular category to show/hide only those images.#
) a particular category to show/hide only those images.#
Ensure no images are currently selected by clicking the ![]()
Deselect icon. Then, single-click to select 2-3 images from the unknown category that best fit the Negative Control category. Once selected, click Categorize in the top right and select Negative Control. Do the same for 2-3 Positive Control images.
3. Train model#
Click on the Classification button under Learning Task then proceed to customize the settings for model fitting by clicking the Fit Model ![]() icon. Within the menu that opens, you can select various parameters to adjust model training. Open the
icon. Within the menu that opens, you can select various parameters to adjust model training. Open the Dataset Settings menu to find the Train percentage field. This value controls what fraction of the images you have annotated will be used to train the model in Piximi. The remainder will be used to test how well Piximi can classify images not previously seen. We will use the default for now.
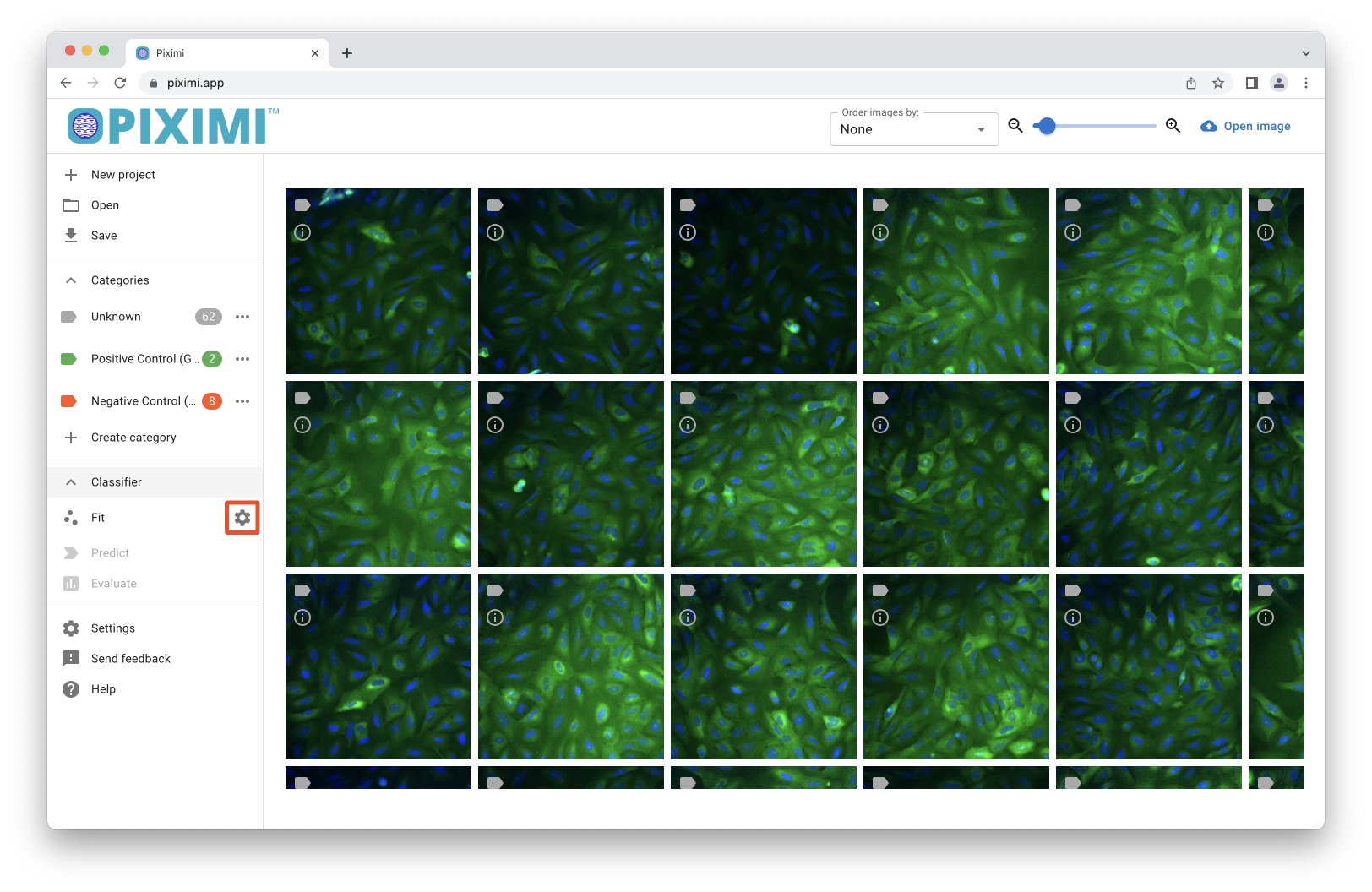
Fig. 24 Open the classifier settings.#
In the top right, click the ![]()
Fit Classifier button to begin training. Piximi will now look at the training subset of the images you have annotated and try to learn what links the input image to a particular class. Then, Piximi will apply what it has learned by examining the validation subset of images and compare the models answers to the image class.
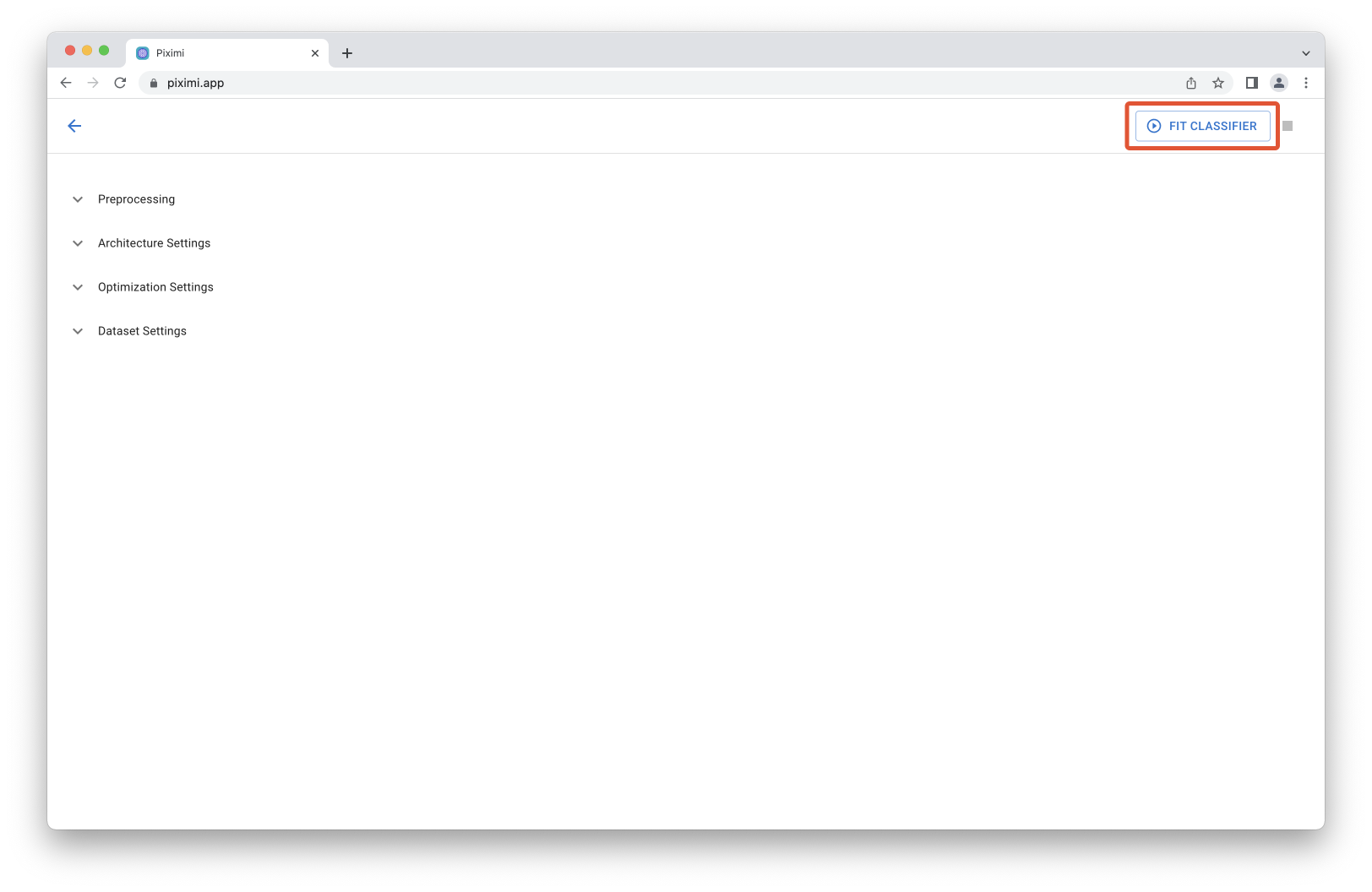
Fig. 25 Explore classifier settings and then press ![]() to begin training.#
to begin training.#
At the bottom of the Fit Model settings page you will see two graphs update as Piximi trains the model; these show the accuracy and loss of the model over incrementing epochs.
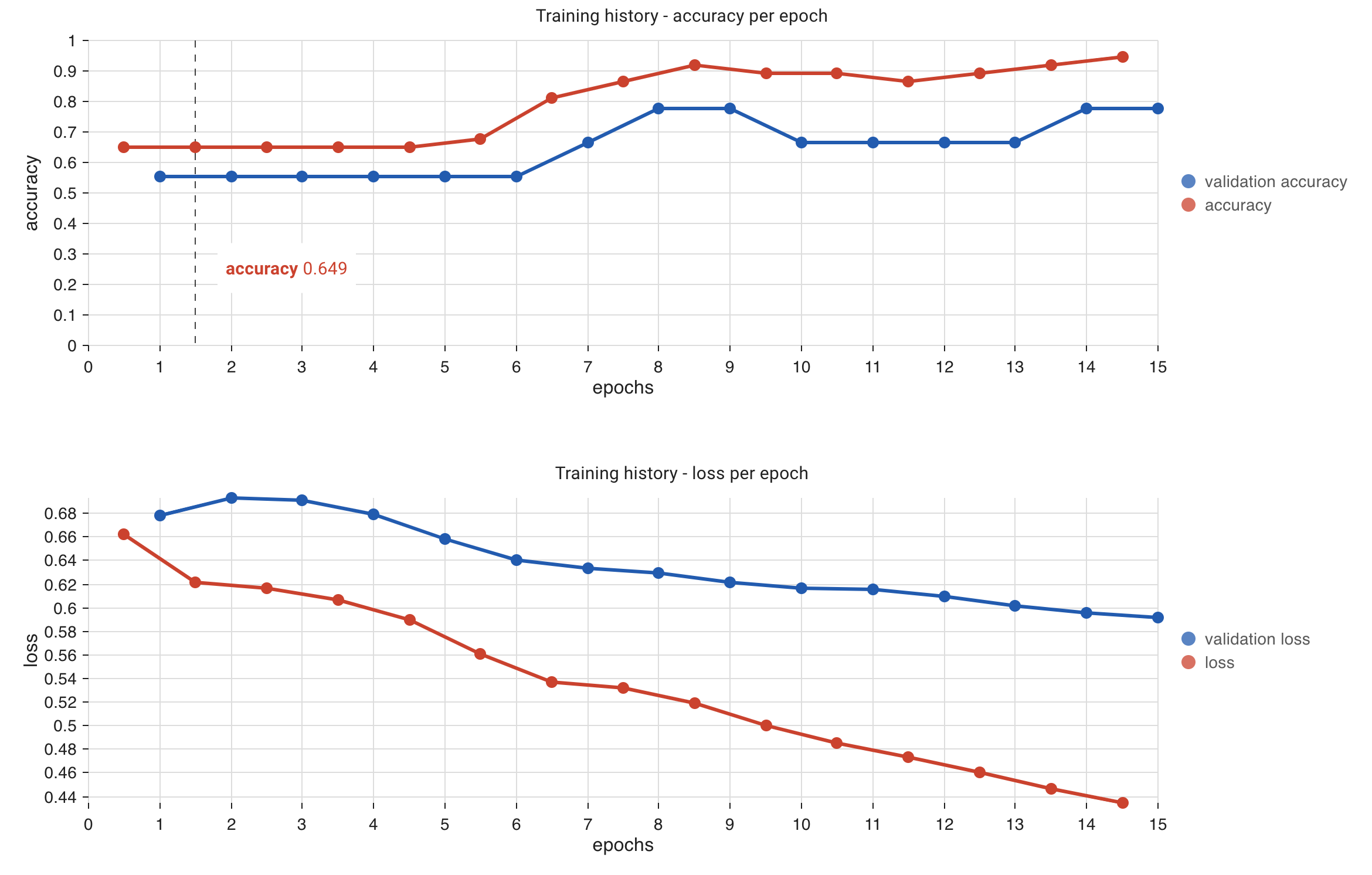
Fig. 26 Training history of a successful classifier model for the U2OS example dataset.#
What is an epoch?
An epoch is a measure of how many times the entire training subset is studied by the deep learning model. As the number of epochs increases, the model optimizes itself to improve classification performance.
However, increasing the number of epochs does not necessarily lead to better results and can instead result in overfitting. Click here to read more about overfitting (needs link).
Accuracy is a measure of how well the model has performed and is calculated as the ratio between the number of correct predictions and the total number of predictions. In this case, Accuracy refers to the accuracy of the model at correctly determining the class of images in the training subset of images.
Validation Accuracy is the accuracy when the model examines the validation subset of the data.
Validation accuracy vs accuracy
If you notice that your Validation accuracy value decreases as epochs increase but your Accuracy measurement continues to increase, this means that your model is fitting to the training subset of data better but your model is losing the ability to accurately predict on new data.
This is a result of overfitting as your model begins to pick up features within your image, such as noise, that are not relevant to classification. In essence, overfitting is when the model memorizes the answer to a specific question, rather than determining the answer from scratch itself.
Loss is another metric that is calculated on the training and validation subsets of data and are depicted as loss and validation loss, respectively. Loss represents a summation of the errors the model has made during classification.
You can now exit the Fit Model settings by clicking the ![]() in the top left of the dialog.
in the top left of the dialog.
Fig. 27 Exit the fit settings menu.#
4. Predict classes for unlabelled data#
Once your model has been trained you can click ![]()
Evaluate to see in-depth metrics on how well the model performed. You can then click ![]()
Predict to run the trained model on the unannotated data. Once an image has been classified you will see the ![]() color on the image thumbnail update to that particular class. At this stage, you may inspect the predicted classes and either accept the predictions by clicking and holding
color on the image thumbnail update to that particular class. At this stage, you may inspect the predicted classes and either accept the predictions by clicking and holding ![]()
Accept Predictionsor reject them by clicking ![]()
Clear Predictions. Depending on the performance of the model, annotating further images based on the predictions and/or adjusting the Fit Model settings may be desired.
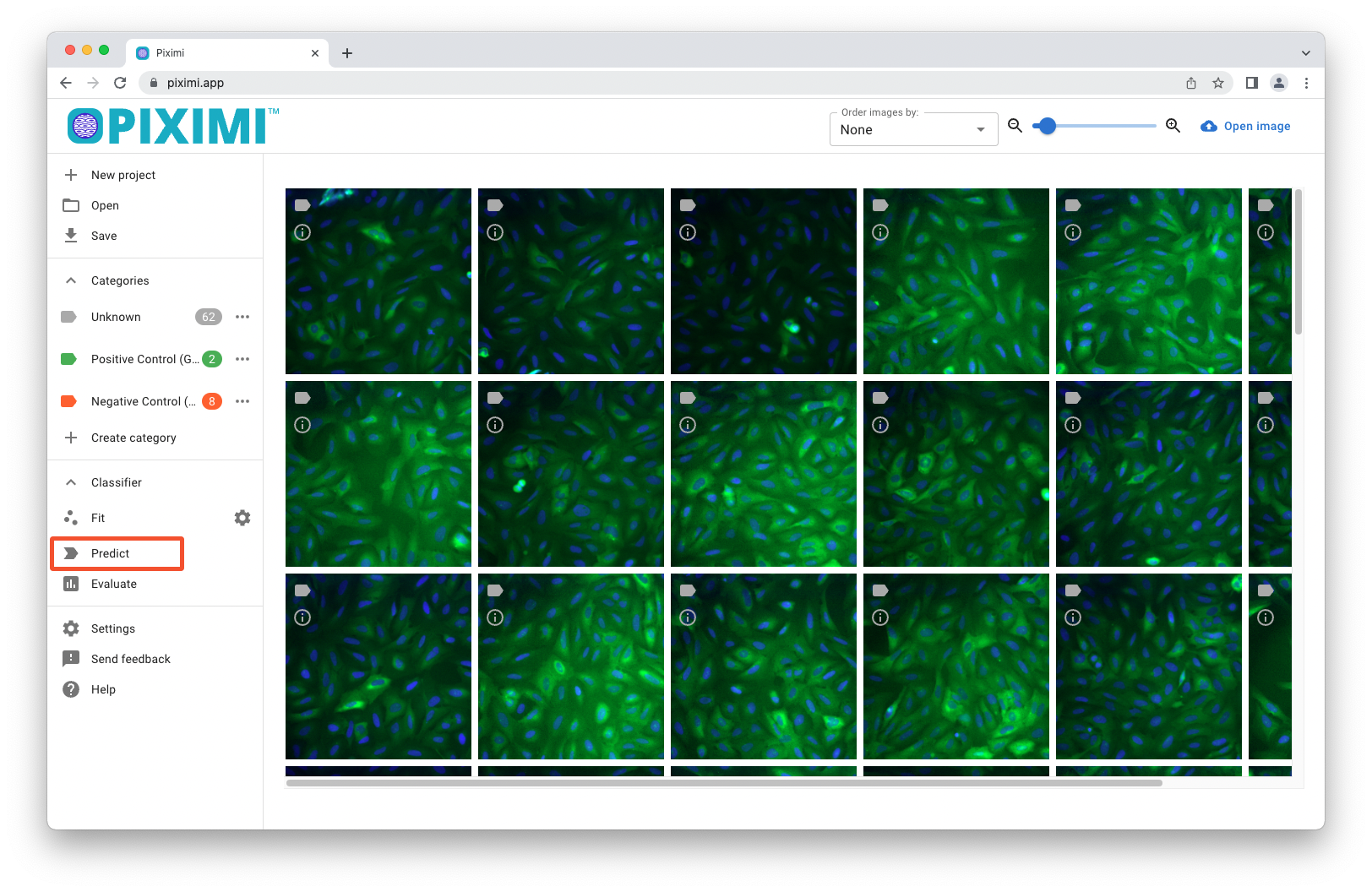
Fig. 28 Predict the class of unknown images using your trained model.#
Copyright
The BBBC016 images used here are licensed under a Creative Commons Attribution 3.0 Unported License by Ilya Ravkin.